Radial basis function network can be
used for approximating function and recognizing patterns. It uses Gaussian
Potential functions.
Architecture
The architecture radial basis function
network consists of three layers, the input,hidden and the output layer as
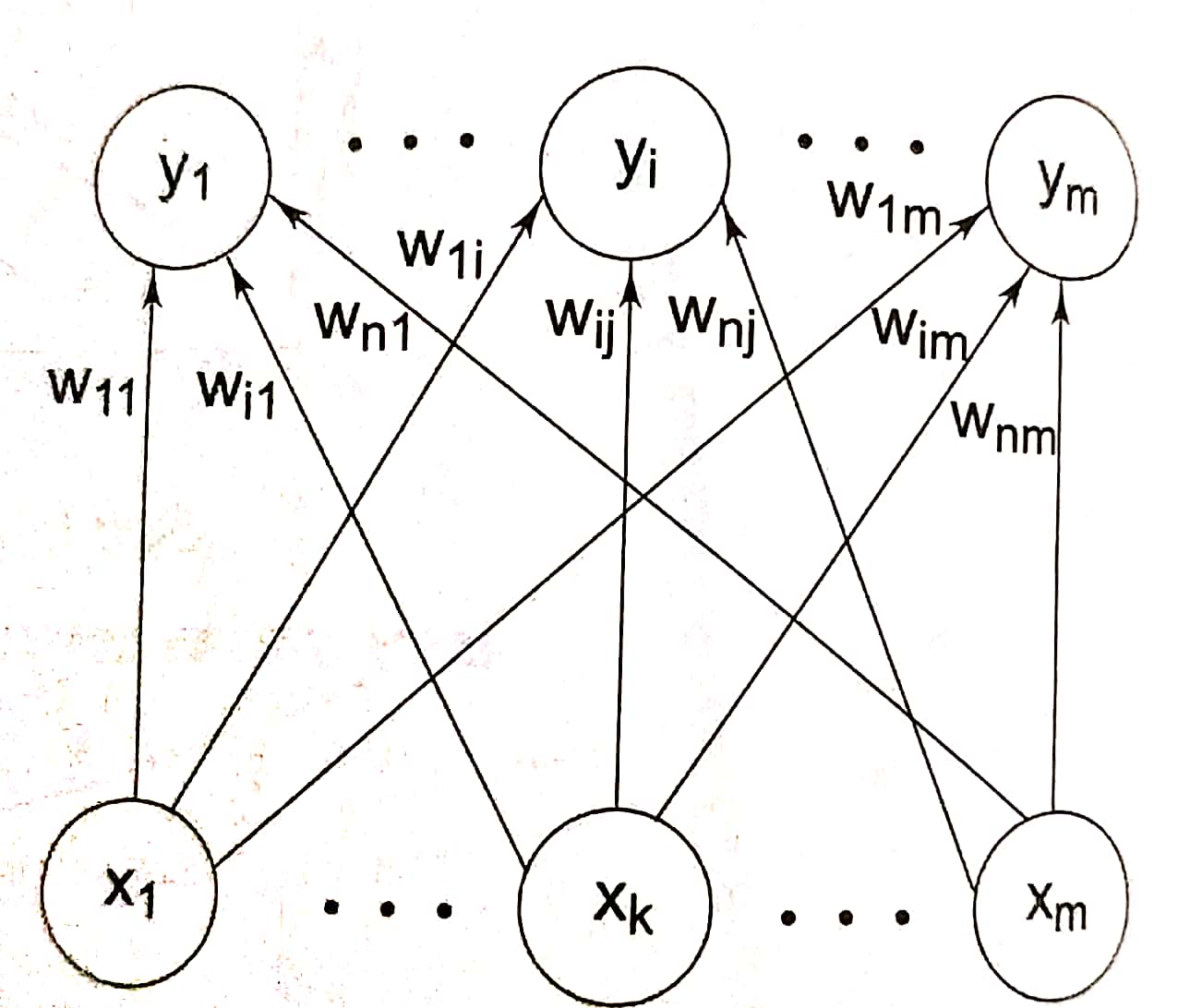
shown in below figure. The architecture of RBFN is a multi layer feed forward
network. There exist ‘n’ number of input neuron and ‘m’ number of output
neurons with the hidden layer existing between the input and output layer. The
interconnection between the input layer and hidden layer forms hypothetical
connection and between the hidden and output layer forms weighted connections.
The training algorithm is used for updation of weights in all the
interconnections.


Training algorithm for RBFN
The training algorithm for the radial
basis function network is given below. Radial basis function uses Gaussian activation
function. The response of such function is non-negative for all value of x. The
function is defined as, f(x)=exp(-x2)
Step 1: Initialize the weights (set to
small random values)
Step 2: While stopping is false do
step 3-10
Step 3: For each input do steps 4 – 9
Step 4: Each input unit (xi ,i=1,2.....n)
receives input signal to all unit in the layer above(hidden unit)
Step 5: Calculate the radial basis
function
Step 6: Choose the centres for the
radial basis functions. The centres are chosen from the set of input vectors. A sufficient number of
centers have to be selected in order to ensure adequate sampling of the input
vector space.
Step 7: The output of im
unit vi(xi) in the hidden layer.
$$ v_i(x_i)=exp(-\sum_{j=1}^r[{{x_{ji}-\bar{x}_{ji}]^2}\over{\sigma^2_i}}) $$
Where $\bar x_{ji}$ = Centre of the RBF unit for input variables
$\sigma _i$ = Width of the RBF unit
$x_{ji}$ = $j_{th}$ variable of unit pattern
Where $\bar x_{ji}$ = Centre of the RBF unit for input variables
$\sigma _i$ = Width of the RBF unit
$x_{ji}$ = $j_{th}$ variable of unit pattern
Step 8: Initialize the weights in the
output layer of the network to some small random value.
Step 9: Calculate the output of the
neural network
$$ y_{net}=e\sum_{i=1}^Hw_{im}v_i(x_i)+w_0$$
Where, H = Number of hidden layer nodes(RBF function)
$y_{net}$ = Output value of the $m_{th}$ mode in output layer for the $n_{th}$ incoming pattern.
$w_{im}$ = Weight between $i_{th}$ RBF unit and $m_{th}$ output node
$w_0$ = Biasing term at $n_{th}$ output node
$$ y_{net}=e\sum_{i=1}^Hw_{im}v_i(x_i)+w_0$$
Where, H = Number of hidden layer nodes(RBF function)
$y_{net}$ = Output value of the $m_{th}$ mode in output layer for the $n_{th}$ incoming pattern.
$w_{im}$ = Weight between $i_{th}$ RBF unit and $m_{th}$ output node
$w_0$ = Biasing term at $n_{th}$ output node
Step 10: calculate error and test
stopping condition.
The stopping condition may be the
weight change, number of epochs, etc.